Glenn Johnson neste artigo abordou fortes razões que nos convencem migrar nossas aplicações para o mundo SQL.
Apresentamos aqui 12 dicas práticas para os desenvolvedores Magic xpa que estão planejando migrar o sistema de dados de Btrieve para bancos SQL:
1ª – Escolha do SQL
“SQL” é um termo genérico e existem vários/diferentes produtos nesta categoria (ex: Oracle, MSSQL, DB2, MySQL, etc…). Cada produto pode definir suas próprias regras de funcionamento. Por isso, o que pode ser verdade para um, pode não ser para outro. A regra é: conhecer bem as características do produto (SGBD) SQL escolhido. Se a intenção é definir regras únicas que sirvam para “vários”, então é necessários conhecer “todos” os escolhidos e adotar o menor denominador comum entre eles.
2ª – Nome dos Objetos
No Btrieve, os campos não possuem nomes nas tabelas físicas (arquivos .DAT). Nem os índices. No SQL, possuem.
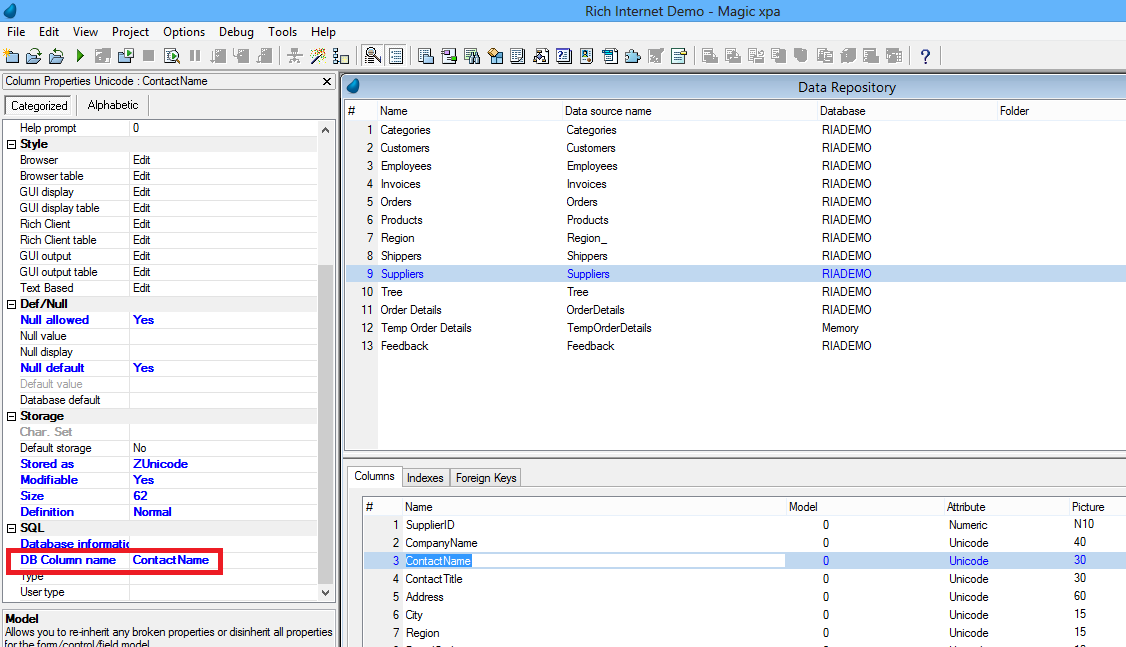
Por isso, é obrigatório definir o ‘DB Column Name’:
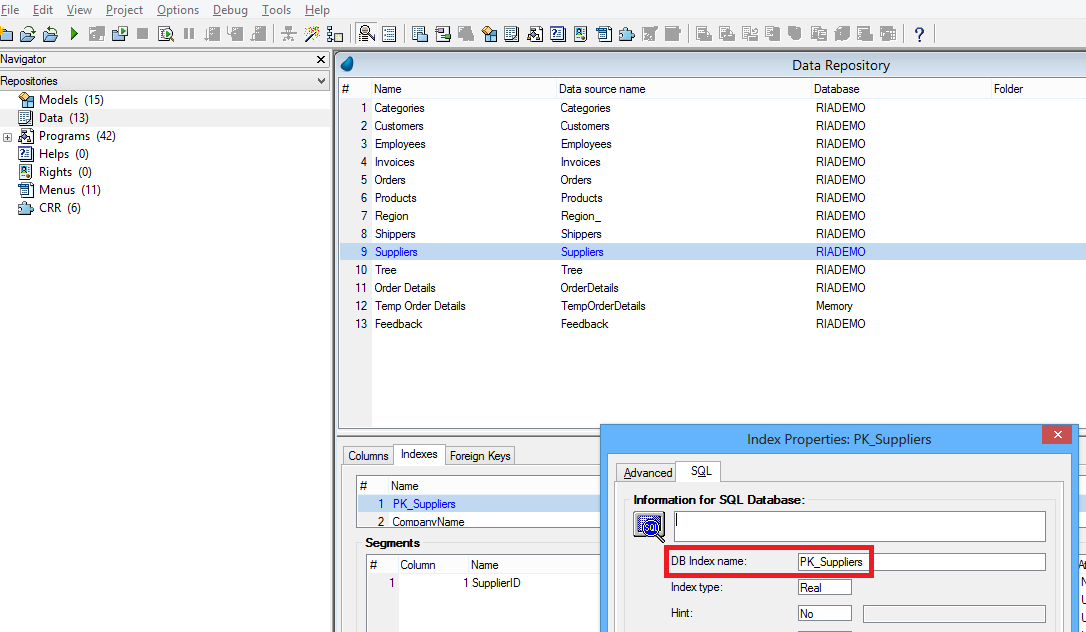
E o ‘DB Index Name’:
Em todos os campos e índices no repositório de dados.
Os nomes de campos (DB Column Name) tem de ser únicos na mesma tabela, mas podem se repetir entre tabelas diferentes. Os nomes de índices (DB Index Name) tem de ser únicos tanto na mesma tabela, quanto em todas as tabelas existentes. Estes nomes precisam também obedecer as regras do SQL quanto a comprimento máximo, não ter espaços, acentos, ponto, vírgula, etc. As regras do SQL para nomes também se aplicam ao nomes das próprias tabelas.
Estas são imposições do SQL, e não do Magic xpa
3ª – Índice Único
No Btrieve, não é obrigatória a existência de um índice único na tabela.
Em alguns SQL, também não.
O Magic xpa porém, exige que cada tabela de banco SQL possua ao menos um índice único:

Estas são imposições do Magic xpa, e não do SQL
4ª – O Índice Não Precisa Existir Fisicamente na Tabela
No Btrieve, todos os índices definidos no repositório de tabelas precisam existir também nas tabelas físicas (arquivos .DAT).
Para o SQL, isso não é obrigatório.
É possível ter um índice que só está definido no Magic xpa, mas não existe na tabela SQL:


Isso porque para o Magic xpa, o índice de uma tabela SQL é usado exclusivamente para montar a cláusula ORDER BY do comando SELECT, no acesso aos dados.
Nestes casos, onde o índice só existe no Magic xpa, ele precisa estar definido como ‘Virtual’:

Esta dica também se aplica a dica #3, pois o índice único obrigatório pode ser apenas ‘Virtual’. Mas neste caso, é importante montar uma combinação de chave que realmente não produza valores duplicados.
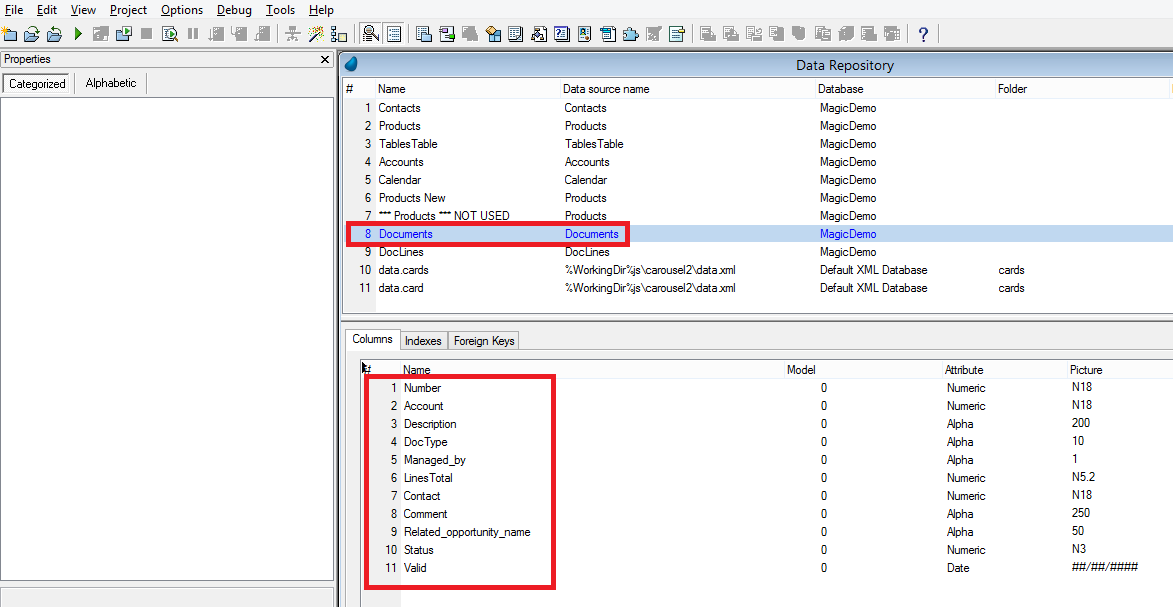
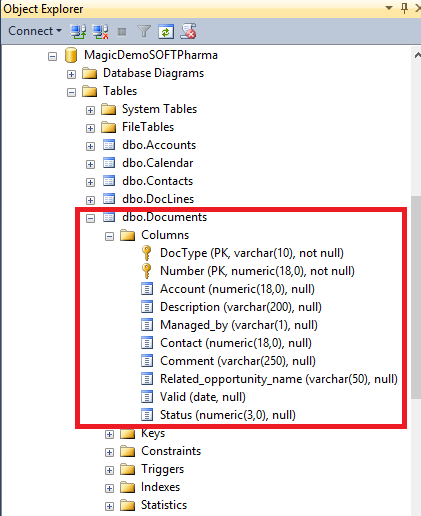
5ª – A Ordem dos Campos é Aleatória
No Btrieve, todos os campos e índices definidos no repositório de tabelas precisam estar na mesma ordem em que eles existem nas tabelas físicas (arquivos .DAT).
No SQL, não.
No SQL, a disposição destes elementos pode ser totalmente diferente do que consta no Magic xpa:
6ª – A Definição de Todos os Campos/Índices Não é Obrigatória
No Btrieve, todos os campos e índices existentes na tabela física (arquivo .DAT) precisam também estar definidos no repositório de tabelas.
No SQL, não.
Você pode definir no repositório apenas os campos e índices que efetivamente precisará acessar:

A restrição para isso, é que os campos deixados de fora do Magic xpa precisam ter sido criados no SQL como nullable e/ou com valor default.
Estas são restrições do SQL, e não do Magic xpa
7ª – Data Zerada
O Btrieve aceita o valor de data zerada ( 00/00/0000 ).
A maioria dos SQL, não.
Por isso, todos os programas e tarefas precisam ser revisados para que qualquer lógica ( expressão ), inicialização de campos ( reais ou virtuais ) ou “input” do usuário ( controles em formulários ) que tenham datas zeradas, sejam ajustados para um outro valor aceito pelo SQL. Normalmente, o padrão adotado é 01/01/1901 ou 01/01/1900. A exceção para isto seria se os SGBD SQL que você escolher aceitarem trabalhar com data 00/00/0000.

Estas são imposições do SQL, e não do Magic xpa.
8ª – Seleção de Colunas no DataView
No Btrieve, é possível incluir no DataView dos programas e tarefas apenas os campos que se deseja utilizar.
No SQL, depende do caso.
Se o programa/tarefa não permitir inclusão (apenas consulta, alteração ou exclusão), pode se aplicar a mesma regra do Btrieve.
Se o programa/tarefa permitir inclusão (Create, Batch Create, Link Create ou Link Write), só pode ficar de fora do DataView os campos criados no SQL como nullable e/ou com valor default.
Por isso, todos os programas e tarefas precisam ser revisados para que os campos que não cumprem esta condição sejam adicionados ao DataView, quando for o caso:

Estas são imposições do SQL, e não do Magic xpa.
9ª – Transações
No Btrieve, as manipulações de dados não são transacionadas.
No SQL, são.
Este assunto é muito extenso para ser coberto com uma simples dica. Estamos inclusive preparando uma série de posts sobre ele. Mas não vamos perder a oportunidade J.
Considerando que não há transações no Btrieve, você se aproxima bastante do mesmo comportamento/resultado com SQL, quando instrui o Magic xpa a não abrir transações explicitamente.
Em programas/tarefas On-Line ou Batch, é com ‘Physicall – None’.
Em programas/tarefas Rich Client, é com ‘None – None’.

Mesmo com estas configurações, as transação ainda existirão (o SGBD SQL as criará). Mas elas terão um tempo de vida (duração) bem mais curto.
Mas ATENÇÃO:
O tipo de ‘Locking Strategy’ que você selecionar para o programa/tarefa poderá impedir que a configuração de transações explícitas seja desativada.
10ª – Desempenho ( Performance )
No Btrieve, que é um sistema ISAM, o acesso aos dados é feitos através de um cursor que navega pela área física das tabelas (arquivos .DAT).
No SQL, o acesso é sempre feito através de um comando de extração (o SELECT) que obrigatoriamente produz um subconjunto de dados (linhas), podendo ser de uma ou mais tabelas. Este comando precisa sempre ser primeiramente analisado (se está correto e é coerente) pelo SQL, para posteriormente ser aplicado (executar a ação solicitada). Para a tabela definida no Main Table também será criado um cursor, mas para o subconjunto da extração e não para a tabela em si.
Esta diferença de metodologia tem um impacto direto na performance da manipulação de dados, à medida que esta quantidade de dados (linhas ou registros) vão aumentando.
A facilidade de desenvolvimento do Magic xpa com a evoluída abstração da camada de acesso aos dados, permite que uma mesma construção (ex: Link Query) funcione tanto com Btrieve quanto com SQL, mesmo com tanta diferença entre eles.
Mas por causa destas diferenças, o que apresenta uma boa performance em um, pode não ter o mesmo resultado em outro.
Vamos avaliar alguns cenários (hipotéticos).
Vamos considerar uma tabela de PEDIDOS, com todas as vendas da empresa nos últimos 8 anos, +/- 400.000 linhas (registros). Seriam mais de 4.100 p/mês, não tá mal J. E uma tabela de CIDADES, com todas as cidades brasileiras. No pedido tem a CIDADE da venda, que liga com a tabela de cidades. Os pedidos são ordenados por número.
Cenário #1: Apagar todos os pedidos dos 3 últimos anos
Em Btrieve, certamente será um Batch Delete, com Range nas datas.
O mesmo pode também ser feito em SQL.
Mas neste caso, isso seria traduzido em enviar um SELECT <…> WHERE <…> e extrair todos os registros que combinam com a faixa (eles poderão viajar do servidor de dados até a máquina que está executando a tarefa). E então, enviar um DELETE <…> para cada registro retornado anteriormente. Se não há necessidade de processamento dos registros antes de sua exclusão (não há nada no Record Prefix/Suffix) desta tarefa Batch, isto poderia ser substituído por uma tarefa Batch D-SQL, enviando explicitamente um comando DELETE <…> para que toda a exclusão fosse realizada no servidor SQL. Isso traria um ganho de performance razoável nesta atividade.
Cenário #2: Criar um Novo Pedido, onde o Número é o Último Existente + 1
Em Btrieve, poderia ser um Link Query Reversed, sem nenhum Locate ou Range, para se verificar qual o último número existente. E depois, somar 1.
O mesmo pode também ser feito em SQL.
Mas neste caso, isso seria traduzido em enviar um SELECT <…> sem claúsula WHERE e extrair todos os registros da tabela de PEDIDOS – os 400.000 – (eles poderão viajar do servidor de dados até a máquina que está executando a tarefa). E então, pegar o último/maior número. Isto poderia ser substituído por uma tarefa Batch D-SQL, enviando explicitamente um comando SELECT MAX <…> para que a seleção do último valor fosse realizada apenas no servidor SQL. Isso traria um ganho de performance astronômico nesta atividade.
Cenário #3: Mostrar todos os Pedido, na tela, para o Usuário
Em Btrieve, certamente será um Main Table, sem Range.
O mesmo pode também ser feito em SQL.
Mas Main Table sem Range é traduzido para SELECT <…> sem cláusula WHERE. Novamente extrairíamos todos os registros da tabela de PEDIDOS – os 400.000 – (eles poderão viajar do servidor de dados até a máquina que está executando a tarefa). Por isso, convém sempre rever a estratégia e definir algum tipo de Range (que será traduzido em cláusula WHERE) mínimo, para que retorne alguns registros por vez, e não todos. Como por exemplo, ter de escolher um período para seleção dos pedidos a serem exibidos.
Cenário #4: Mostrar os registro na tela, em um Grid ( Table ).
Para mostrar dados em Grid, o Magic xpa precisa fazer três controles: qual é o registro atual, quais são os registros anteriores (ao atual) e quais são os próximos (ao atual), segundo os critérios de ordenação. Isto é mais custoso de se realizar em SQL. Por isso, nos casos em que o Grid pode ser substituído pelo Screen Mode ( um registro do Main Table na tela, por vez ), isso também melhorará a performance.
Cenário #5: Relatório de todos os PEDIDOS com dados também das CIDADES.
Em Btrieve, certamente será um Main Table em PEDIDOS, com LinkQuery nas CIDADES.
O mesmo pode também ser feito em SQL.
Porém, cada LinkQuery que não puder ser trocado pelo cache de um anterior, implica em uma nova instrução SELECT enviada para o SQL (podendo ser uma para cada registro retornado no Main Table).
Em vários casos, o LinkQuery pode ser substituído pelo LinkJoin. O LinkJoin faz com que os registros do Link retornem junto com os registros do Main Table, na mesma instrução SELECT. A diminuição de instruções SELECT enviadas ao SQL também melhora a performance da atividade.
Cenário #6: Relatório de todos os PEDIDOS com dados também das CIDADES, mas apenas da UF ‘RS’.
A informação da UF não existe nos PEDIDOS, apenas nas CIDADES.
Em Btrieve, poderá ser um Main Table em PEDIDOS, com LinkQuery nas CIDADES. E um Range diretamente nas CIDADES (Link), pela UF.
O mesmo pode também ser feito em SQL.
Em qualquer dos casos, SQL ou Btrieve, não será um processo rápido. Isso porque todos os registros de PEDIDOS serão extraídos (não tem Range em PEDIDO), e na máquina que está executando a tarefa é que haverá a seleção de quais são válidos (onde a CIDADE é da UF ‘RS’).
Mas para o caso do SQL, existe a opção do LinkInnerJoin.
O LinkInnerJoin alteraria a cláusula WHERE de seleção dos PEDIDOS, de forma que esta filtragem ocorra toda ela no SGBD, retornando na extração apenas os registros que efetivamente são válidos. Isso traria um ganho de performance astronômico nesta atividade.
Cenário #7: Definição de Range no CTRL+R da Tarefa.
Algumas formas de definição de Range irão obrigar a que todos os dados sejam extraídos no SGBD, e a filtragem ocorra na máquina que está executando a tarefa (ex: Range por expressão). Outras, forçarão que a filtragem ocorra diretamente no SGBD, e retornem apenas os registros válidos. É importante observar estas diferenças. Toda filtragem (Range) que puder ser resolvida diretamente no SGBD, terá um resultado muito melhor em performance.
Cenário #8: Definição de Sort no CTRL+T da Tarefa.
O mesmo que foi dito no cenário #7, definição de Range, também se aplica para o Sort.
11ª – Fuja das Chaves “Auto-Incremento”
🙂
Esta, provavelmente você não queria receber.
Quando se entra no mundo SQL, uma grande tentação é utilizar os tipos Auto-Incremento. Especialmente para chaves. Toda a facilidade de não ter de se preocupar com a chave única, etc… Mas é tudo um engano. Chave Auto-Incremento traz muito mais problemas do que alegrias. Por exemplo: Você tem uma tabela com este tipo de chave, e precisa copiar estes registros para outra tabela, ou outra base de dados.
Eles entrarão lá com outra chave. A intenção é que seja o mesmo registro (conteúdo), apenas em outro lugar. Mas na prática, é como se fosse um outro registro. Você não consegue trazê-lo de volta, por exemplo, sem um controle entre chave original x chave nova.
Outro caso: você define uma relação PAI x FILHO entre tabelas e a chave do PAI é Auto-Incremento. Você precisa deste valor para inserir FILHOS, mas ele não existe enquanto o PAI não for fisicamente inserido. Isso obriga muitas vezes a montar lógicas mirabolantes, que só dificultam o desenvolvimento e a manutenção.
Quer uma dica útil? Sai dessa!
Chave primária tem de ser um valor que você define e usa quando quiser. Mas ela está na sua mão.
Um modelo que me agrada para chave única, só para fins de exemplo, é um campo CHAR(49) (não seja mesquinho com tamanho de campos), sendo definido como: DStr(Date(),’YYYYMMDD’) & mTStr(mTime(),’HHMMSSmmm’) & <GUID>. <GUID> seria um valor GUID, sem ‘–‘, ‘{‘ ou ‘}’, com 32 caracteres de tamanho. Usar a data/hora no início da chave dá uma conotação cronológica à existência do registro e também agiliza a atualização dos índices, já que o próximo valor muito provavelmente será o maior e terá de ir no final da lista encadeada. E usar o GUID garante o valor único.
Mas é apenas uma questão de preferência.
Você pode ter outras :-).
12ª – Fuja do “NULL”
🙂
O SQL permite que qualquer campo de uma tabela, exceto aqueles que fazem parte de algum índice, sejam definidos como nullable. Campos deste tipo podem, ao invés de valor, conter NULL, que significa <sem conteúdo> ou <conteúdo nulo>.
O problema são as computações com este tipo de conteúdo, ou em Magic xpa, as expressões.
Se tivermos um campo numérico, por exemplo <ValorTotal>, e montarmos uma expressão:
<ValorTotal> * 2
Em Btrieve sempre resultará no sobro do valor do campo.
Já em SQL, se <ValorTotal> for NULL o resultado da conta será: NULL. E isso é um porta, bem larga, para bugs de lógica. Um teste adicional será sempre necessário com estes campos, do tipo:
IF( ISNULL( <ValorTotal> ), <…>, <…> )
Trazendo mais complexidade ao desenvolvimento e manutenção.
Mas se quiser mesmo, ou tiver que, trabalhar com campos nullable (você pode precisar manipular bancos de outros sistemas), uma configuração interessante do Magic xpa é o NULL Arithmetic:

Mudando esta configuração para ‘Use Default’, você estará instruindo o runtime Magic xpa para testar automaticamente todos os campos usados em expressões, e mudar o valor NULL para o valor default do campo, antes de fazer as computações (mudar apenas na expressão).

Ótimo artigo para quem está pensando em efetuar a migração (como eu).
No caso do SGBD Oracle, pode ser usado a propriedade de auto incremento SEQUENCE, porém apenas para valores do tipo numérico. Para inserção de valores não numéricos ou numéricos de ordenação diferente da SEQUENCE, basta apenas inserir normalmente o valor desejado, não sendo necessário comandos como o IDENTITY_INSERT ON utilizado no SQL Server. Um TRIGGER pode ajudar na automatização deste processo.
‘Identity’ é um recurso do MS-SQL. Não existe no Oracle, por exemplo…
Excelente artigo! Já havíamos observado todas estas situações em nossas conversões do Pervasive 2000i para o SQL Server 2008 R2.
Discordo apenas no caso das chaves auto_incremento, onde estas podem ser manualmente atribuídas ao utilizar a instrução SET IDENTITY_INSERT ON; Junto ao SGBD (MSSQL).
Nossa maior dificuldade foi na atualização dos DataSources, visto que ao utilizar o recurso “Get Definition (F9)” do Magic XPA, os programas perdem a referência dos objetos e seus campos.
No mais, em questão de performance e escalabilidade, o SQL chega a surpreender. Vale a pena migrar!