 Big Data apresenta o desafio de gerenciar grandes quantidades de informação. No entanto, o aumento de dados é apenas metade da história. Metadados, que no passado foi limitado a nomes e rótulos, hoje engloba informações sobre as relações entre os dados, relatórios e processos e, devido ao seu volume crescente exige a sua própria estratégia para a gestão eficiente.
Big Data apresenta o desafio de gerenciar grandes quantidades de informação. No entanto, o aumento de dados é apenas metade da história. Metadados, que no passado foi limitado a nomes e rótulos, hoje engloba informações sobre as relações entre os dados, relatórios e processos e, devido ao seu volume crescente exige a sua própria estratégia para a gestão eficiente.
Tudo precisa continuar: Gerenciando os dados
Parte do grande volume de metadados são criados por middlewares que são usados para integração de sistemas. Middlewares são culpados da geração do Big Metadata pois quando processos de negócios englobam aplicações, é necessário manter um Armazenamento de Dados Operacionais (ODS – Operational Data Store) para todos os dados que fluem pelo sistema. Metadados são logados no ODS antes dos dados serem manipulados, depois ou ambos momentos. Com a tendência atual de abordagem de dados de “manter tudo”, o ODS está crescendo em tamanho e tornando-se difícil de gerenciar. Além disso, aas mensagens que fluem entre a API de uma aplicação e o servidor do middleware contém metadados que consumem processamento, memória e banda larga.
Em muitas situações, reduzir o tempo que se leva para extrair valor de todos estes dados é um requisito essencial para o sucesso. Por exemplo, AppNexus, um ad exchange online, processa entre 200 e 275 mil ofertas de publicidade online por segundo com um tempo de resposta esperado de menos de 100 millisegundos. Devido a grandes volumes de dados, eles dizem que algumas vezes, pode levar três minutos para atualizar o cache. De acordo com Brian O’Kelley, CEO da Appnexus, a latência na rede pode custar USD 10.000 por minuto.
Reduza a Latência, Aumente a Eficiência
Uma abordagem tecnológica comum para redução de latência é a utilização da computação em memória. Processar os dados assim que chegam, sem ter que gravá-los antes em uma base de dados pode trazer benefícios de performance e redução de dados. Evitar a necessidade de gravar valores intermediários em disco elimina outra fonte de latência introduzida.
Instituições financeiras tem usado computação em memória para detecção de fraudes de cartões de crédito e de atividades comerciais realizadas por robôs há muitos anos. Enquanto isso, o Google utiliza abordagens em memória para buscar grandes quantidades de dados. Metadados também podem ser usados para potencializar as funções em tempo real da plataforma.
Além disso, melhorar o gerenciamento de dados pode incrementar a eficiência no processamento de metadados. Quando os dados são recebidos por uma camada de middleware por causa da integração de dados, isto pode ter diversos destinos; podem ser transferidos para outra aplicação ou fila de mensagens, convertidos para outros formatos, salvos em uma ou mais tabelas ou bases de dados, ou até usados para determinar outras ações. Todos estes processos podem ser examinados e melhorados para uma maior eficiência.
Por exemplo, uma maior eficiência pode ser conquistada usando declarações diretas para atualizar apenas informações que tenham mudado, ao invés de atualizar a tabela toda. Em cenários baseados em eventos ou em tempo real, um simples fluxo pode ser criado para atualizar apenas um campo ou dado. Para cortar os volumes de metadados, mais comandos eficientes podem ser usados, tais como Replicate_Last_Updates para atualizar apenas as mudanças ou Multicast para atualizar simultaneamente múltiplos clientes.
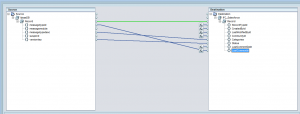 Visualizando Fluxos de Dados
Visualizando Fluxos de Dados
Para analisar os processos mais eficientes para manipular metadados, é de grande ajuda utilizar ferramentas de design que ajudem a visualizar fluxos de dados. Um dos meios mais poderosos e eficientes de visualizar as instruções para manuseio de dados e metadados é através do uso de um serviço de mapeamento de dados.
Um serviço de mapeamento de dados normalmente mostra a fonte de dados na esquerda e o destino na direita e fornece ferramentas para conectar visualmente linhas de dados entre campos de fonte e destino, enquanto aplica funções de negócios ou expressão lógica para fins de transformação. Passos antes e depois de utilizar um serviço de mapeamento de dados também pode conter lógica de manipulação e pode ser visualizado através de um fluxograma de integração.
Linguagem de Execução de Processos de Negócios (BPEL) é um exemplo de abordagem de visualização muito útil. Como a lógica de um fluxograma de integração ou serviço de BPEL podem ser aninhados para conectar outros fluxos de integração ou serviços BPEL, os recursos são extremamente versáteis e poderosos. Administrações adequadas destes recursos podem consuzir a uma melhor manipulação de dados e eficiência de metadados.
Se preparar para Big Metadata significa se certificar que você tem uma estratégia para adoção de técnicas de computação em memória para poder ter poder de processamento disponível. Tomar medidas adicionais para avaliar seu uso atual de práticas ultrapassadas e ineficientes de ETL, gerenciamento de dados, armazenamento de dados operacionais, e dados de integração e práticas de gerenciamento de metadados também ajudarão a deixar seu big metadata sob controle.
