(agora com GigaSpaces)
 Em alguns outros posts (como este) e vídeos (como este) que produzimos ao longo do tempo, tentamos reforçar algumas ‘boas práticas’ do desenvolvimento de projeto de integração/automação com o Magic xpi.
Em alguns outros posts (como este) e vídeos (como este) que produzimos ao longo do tempo, tentamos reforçar algumas ‘boas práticas’ do desenvolvimento de projeto de integração/automação com o Magic xpi.
Algumas delas na verdade são mais do que boas: são essenciais.
E neste post queremos abordar uma em específico: a política de recuperação.
Políticas de Recuperação
A política de recuperação é uma diretriz nos fluxos de integração do Magic xpi que orienta o que deve ser feito em caso de uma exceção grave (popular: erro FATAL ou CRASH).
Exceções são eventos inesperados (ou indesejados) que sempre podem ocorrer durante a execução de um fluxo (sequência de tarefas), e não temos como eliminar a possibilidade de que elas apareçam. Temos é que nos preparar o melhor possível para lidar com elas.
Vejamos como exemplo, o fluxo abaixo:
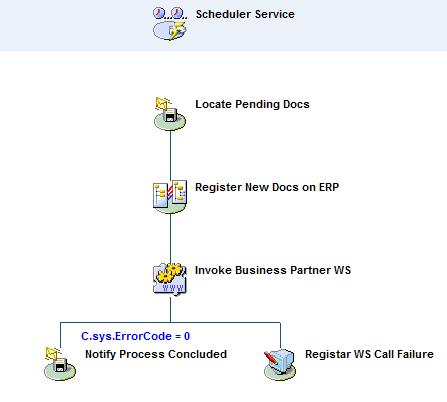
Nele, estamos testando se a chamada do webService (Invoke Business Partner WS) foi bem sucedida, e definindo uma sequência lógica diferente em função da resposta do teste.
Ou seja: preparamo-nos para uma possível exceção.
As possíveis exceções exemplificadas acima são consideradas exceções normais (popular: erro NÃO FATAL). Estavam previstas dentro da lógica do componente webService, tanto que ele irá atualizar a variável C.sys.ErrorCode com o resultado (sucesso ou insucesso) da sua operação. Já são conhecidas.
Mas muitas vezes, ocorrem exceções não previstas na lógica interna dos componentes, ou do orquestrador de fluxos do Magic xpi.
Estas são as exceções graves (também chamadas de ‘crash’), e a única forma de nos precavermos quanto a elas é com a adoção de políticas de recuperação:
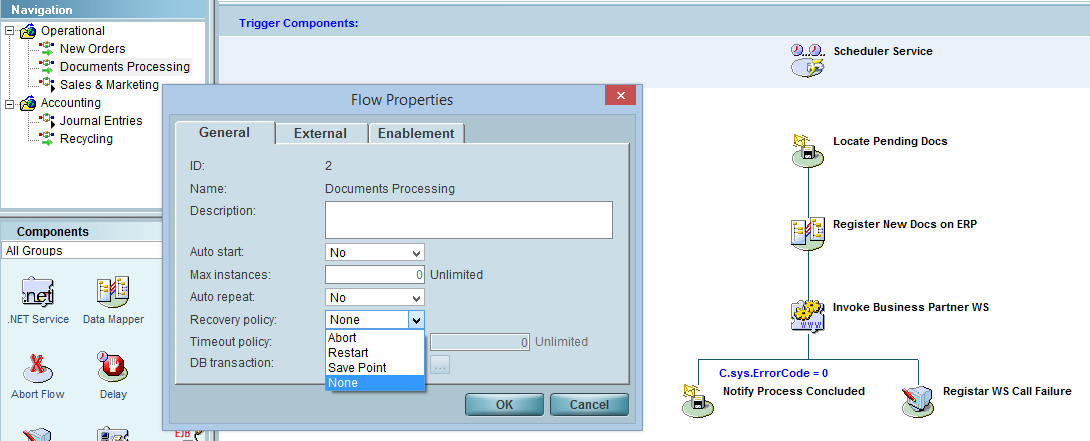
Quando um fluxo é criado no Magic xpi Studio, a política padrão dele é ‘None’ (não fazer nada).
Ou seja: se ocorrer uma exceção grave, o que já foi feito ‘está pronto’ e o que faltava fazer, ‘paciência’. Na ausência de política explícita, e política implícita e deixar o barco correr.
Este é um ponto de atenção muito importante: faz parte da lógica da integração definir o que deve ocorrer em caso de exceções graves. É inclusive tema do treinamento de Magic xpi. O arquiteto da integração não deve omitir esta etapa, negligenciar esta avaliação.
A decisão final pode até ser definir o Recovery=None, mas isso tem de ser uma coisa consciente, pensada e decidida em função da natureza do fluxo de integração. Não pode ficar assim só porque é a configuração default.
A política aplicada pode ser a diferença entre sucesso e o fracasso da integração que está sendo desenhada.
Como mencionado anteriormente, políticas de recuperação são diretrizes.
Diretrizes para quem? Para o GigaSpaces.
Nenhum fluxo inicia a executar, sem que haja um Work Message para ele dentro do GigaSpaces. Quando um Worker (thread) do Magic xpi se apropria de um Work Message, ele é responsável por atualizá-lo periodicamente, incluindo o momento da conclusão do fluxo. Quando estas atualizações deixam de ocorrer dentro do período esperado, o GigaSpaces entende que uma exceção grave (crash) ocorreu, e procura pela política de recuperação que deve aplicar para esta situação (ela está gravada no Work Message do fluxo).
Obviamente que se estiver definido Recovery=None, nada será feito.
E está claro também, que pela natureza da lógica de detecção de ocorrências de exceções graves, pode levar um tempo (segundos ou minutos) até que a política desejada seja efetivamente aplicada.
Numa execução de fluxo de integração Magic xpi, são dois o tipos de exceções graves que podem ocorrer:
Thread Crash
É quando o Worker (thread) do Magic xpi é abortado, mas o Magic xpi Server continua operando normalmente. Somente a thread cai. Esta exceção não é aparente, já que se consultarmos os processos do sistema operacional, vamos encontrar todos lá. É o clássico: está tudo no ar, mas parou de rodar.
Quando ocorre uma ‘thread crash’, um novo Worker é criado para compensar o que se foi, e em caso da política de recuperação estar definida como ‘Restart’ ou ‘Save Point’, o fluxo de integração é reiniciado.
‘Thread crash’ deixa rastro. Na pasta %magic_xpi_home%logs haverá um arquivo de log com o nome: <projeto>_error.log, e dentro dele, informações associadas ao código de erro -139:
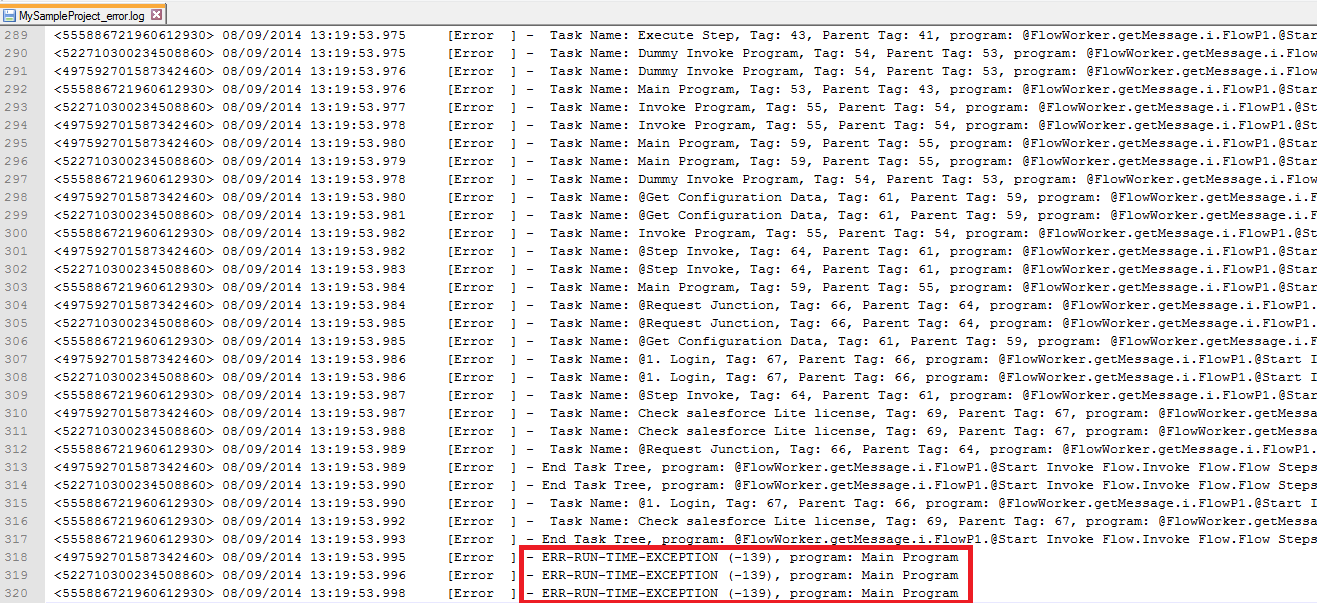
Fluxos de integração que tem a sua lógica atrelada a sua própria conclusão (ex: a última etapa do fluxo é o agendamento da sua próxima execução) são muito sensíveis a uma ‘thread crash’: se não chegar até o fim, não se agenda novamente e sua lógica ficará quebrada – a integração simplesmente para, ainda que o Magic xpi Server continue on-line.
Isso só vem reforçar a importância e relevância das políticas de recuperação.
Server Crash
É quando processo Magic xpi Server é abortado. ‘Server Crash’ geralmente vem precedido de uma ‘Thread Crash’ e se deve ao fato desta (ou destas) ‘thread crashes’ terem sido tão severas, que o processo em si não resistiu e caiu.
Quando ocorre um ‘server crash’, um novo Magic xpi Server é iniciado para compensar o que se foi, e em caso da política de recuperação estar definida como ‘Restart’ ou ‘Save Point’ em algum dos fluxos de integração ativos no momento do crash, estes são reiniciados.
Causas das Exceções Graves (Crashes)
Em função de nossa experiência no mundo Magic xpi, temos observado ao longo do tempo que são três as principais causas de ‘Thread Crash’:
Erros de Desenvolvimento
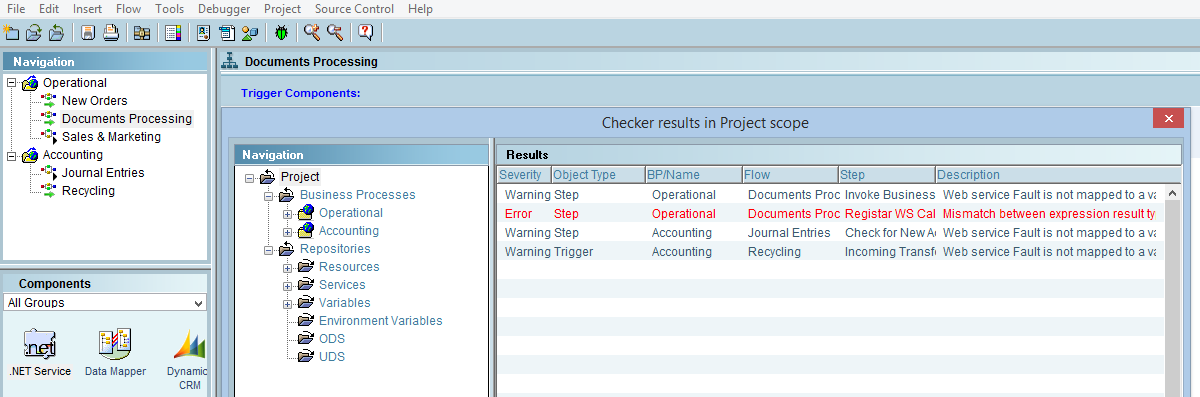
Advertências são até aceitáveis, mas em hipótese nenhuma o desenvolvedor pode liberar para execução um projeto que não passa no Checker (apresenta erros). A probabilidade de ocorrer um crash no momento de executar a etapa que está com erro, é bem grande.
Erros de Acesso a Dados
Algumas falhas de acesso à base de dados pelo Magic xpi Server, seja por erro de configuração ou outro motivo qualquer, pode gerar um crash. Não são comuns estas situações, mas podem ocorrer.
Excesso de Memória RAM alocada na Thread (Worker)
Esta situação pode ser até frequente em alguns projetos, dependendo de como eles são desenhados. De certa forma, poderia também ser classificada como ‘erros de desenvolvimento’, já que em geral é possível prevenir a maioria das situações.
Veja o exemplo abaixo, onde se faz um consulta (query) em uma base de dados para se realizar um ‘bulk load’ no Salesforce:
Uma tarefa simples e fácil: A partir do ‘record set’ retornado na consulta, será construído um CSV a ser enviado ao Salesforce (segundo a definição da API bulk do Salesforce).
Mas, e se houverem muitos registros retornados neste ‘record set’, o CSV não ficará muito grande? Se ele ficar com 200MB, 400MB, isso não será demais para a memória da thread (worker)?
Não há uma fórmula Excel para responder isso, mas o volume de dados manipulados é uma variável muito importante na análise do processo de integração. Lembre-se: toda variável (fluxo, contexto ou global) residirá na memória RAM do Worker (thead). Umas mais tempo, outras menos, mas irão para lá em algum momento.
O arquiteto da integração precisa antever possíveis excessos, e preparar a integração para isso.
A mesma técnica empregada para ocupar o Worker por pouco tempo (ver aqui), em função da otimização do uso da licença, pode ser usada nestes casos também: processar os dados em blocos menores.
Assim, tentamos evitar os crashes por excesso de RAM alocada na thread (Worker).
Outros que podem se tornar vilões nesta história são o BLOBs.
Quando estamos criando Xmls, Txts, CSVs, ou carregando o conteúdo de arquivos por exemplo, provavelmente estaremos usando BLOBs para guardar este conteúdos, mesmo que temporariamente.
No próprio exemplo acima, com Salesforce, os dados selecionados provavelmente foram salvos em um BLOB antes de serem despachados ao sistema final.
E como eles são “variáveis de memória“, a probabilidade de se multiplicarem em cópias é bem razoável. Se passamos um BLOB como parâmetro para um fluxo, por exemplo, imediatamente teremos duas cópias dele em memória. E isso pode se repetir varias vezes durante a execução da lógica.
Por ser um tipo de variável que aceita conteúdos binários ou de texto, até o limite nominal de 2GB, eles se tornam a armadilha perfeita.
Ter uma noção aproximada do tamanho que os BLOBs podem assumir durante a execução dos processos é importante, pois eles também pode gerar um excesso de memória RAM alocada na thread (Worker).
O limite de 40MB ou 50MB parece razoável, na hora de se popular BLOBs. Ficar dentro destes limites deve ser uma meta quando utilizarmos este tipo de variável.
Para evitar a existência de BLOBs com conteúdo muito grande, podemos repetir a estratégia de processar os dados em blocos, mencionada anteriormente.
Chegando ao fim, tentamos então mostrar a importância da análise cuidadosa das exceções dos processos de integração, para o sucesso dos projetos.
Sabemos que torna o desenvolvimento um pouco mais trabalhoso, e pode ter impacto inclusive no volume de horas para concluir as tarefas.
Mas estas questões são de suma importância para o sucesso, e como é de praxe, todo trabalho bem feito requer naturalmente mais cuidado e esforço.

Para receber os artigos do Blog Magic Brasil em primeira mão no seu email, registre-se aqui